L'équité (Fairness) dans le Machine Learning
Cet article a été écrit par Mickael Fine pour la saison 8 de Data For Good.
Cet article tente d'éclaircir le sujet complexe et vaste de l'équité dans le machine learning. Sans être exhaustif, il propose un certain nombre de définitions et d'outils très utiles que tout Data Scientist doit s'approprier pour aborder ce sujet.

L'utilisation du Machine Learning progresse rapidement autour de nous. Depuis quelques années maintenant, de nombreuses entreprises et institutions commencent à prendre conscience de la richesse cachée dans leurs données et ont développé des projets pour exploiter ce potentiel.
Aujourd'hui, depuis un certain temps, les algorithmes ont un impact sur notre vie, qu'il soit mineur (les annonces que nous voyons en naviguant, ou les films qui nous sont recommandés dans Netflix) ou majeur (être sélectionné pour un entretien d'embauche, pour une admission aux universités et grandes écoles, ...). Les compagnies d'assurance utilisent depuis longtemps des algorithmes pour déterminer les tarifs qu'elles appliquent aux particuliers, en fonction de l'âge, de l'état de santé et d'autres critères.
Comment pouvons-nous savoir si nous sommes traités équitablement par ces algorithmes par rapport à toutes les autres personnes qui nous entourent ? Les développeurs savent-ils s'ils introduisent des biais dans leurs algorithmes ?
Ce domaine d'étude est apparu récemment, et nous avons vu apparaître partout des articles sur l'IA digne de confiance, couvrant plusieurs sujets, tels que :
La non-discrimination
Le respect de la vie privée
La robustesse
La sécurité
La transparence
Le présent article traite de la non-discrimination, de l'équité du machine learning et de conseils pour les Data Scientists afin d'améliorer leur travail pour construire une IA plus juste.
Tout d'abord, qu'entendons-nous par "équité" (fairness) ? C'est un point très délicat.
Les chercheurs, les politiciens et toutes les personnes impliquées dans le sujet ne proposent pas de définition consensuelle de l'équité. Il existe en effet de nombreux types de “fairness” qui pourraient être utilisés, comme nous le verrons plus loin dans cet article. En outre, chaque type d'équité nécessite des décisions et des compromis techniques et non techniques, qui ne sont pas faciles à mettre en place.
Discrimination
La discrimination est définie comme le traitement injuste ou préjudiciable de personnes et de groupes sur la base de critères tels que
L'âge
L’handicap
La langue
Le nom
La nationalité
L’orientation politique
La race ou l'origine ethnique
La région
La croyances religieuses
Le sexe, caractéristiques sexuelles, genre et identité de genre
L’orientation sexuelle
La liste est très longue, car elle englobe toutes les caractéristiques qui peuvent être utilisées pour traiter les individus d'une manière différente.
En tant qu'être humain, il n'est pas toujours facile d'identifier les préjugés, ou de voir quand une personne est traitée différemment d'une autre. Nous percevons toujours les choses à partir de nos préjugés personnels, qui proviennent de notre histoire personnelle, de notre culture, de notre morale, de nos opinions, ...
L'exemple de COMPAS
En 2016, le logiciel américain d'évaluation des risques criminels appelé COMPAS a été analysé et les chercheurs ont découvert qu'un préjugé racial majeur était intégré dans l'algorithme. Ce produit a été utilisé pour prédire le risque de récidive criminelle en générant un score de risque de récidive. Les résultats montraient un biais en faveur des blancs (les noirs se voyaient associés à un risque de récidive criminelle beaucoup plus élevé que celui des blancs).




https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms
De nombreux articles ont été publiés sur le problème de Compas, et certains d'entre eux montrent que le problème ne réside pas seulement dans la création de l'algorithme, mais aussi dans son utilisation, et c'est là toute la complexité.
En fait, nous verrons plus loin dans cet article qu'un algorithme ne peut pas satisfaire tous les critères d'équité, et que les métriques utilisées pour créer l'algorithme doivent être parfaitement comprises pour l'utiliser correctement.
L'algorithme Compas a été construit pour répondre aux critères d'équité de la "predictive parity" et n'était pas censé satisfaire toutes les mesures d'équité (ce qui n'est pas possible). Le score de récidive n'aurait pas dû être utilisé pour classer les personnes sans une évaluation approfondie de leur situation sociale. La mesure d'équité utilisée aurait dû être mieux comprise par les autorités pénales américaines afin d'appliquer l'algorithme avec plus d'équité.
Si vous souhaitez en savoir plus sur les recherches menées sur ce sujet, vous pouvez vous référer aux deux documents suivants, qui démontrent la complexité de la construction du bon algorithme :
L'exemple de la carte Apple
Un autre exemple explicite de discrimination massive est le mécanisme d'octroi de la carte Apple, illustré par les tweets suivants :

Il existe de nombreux autres exemples de discrimination.
De nombreux articles ont été publiés sur ce sujet.
Pourquoi cela peut-il se produire ?
Comment un développeur peut-il savoir qu'il introduit un biais dans son algorithme ?
Quand on parle d'un algorithme utilisé en production, on parle d'un “Data product”. Et pour comprendre et donner quelques indices sur la façon d'améliorer l'équité d'un algorithme, il est important de revenir sur la base de ce qu'est un “Data product”.
Le cycle de vie d'un Data product peut être modélisé en deux grandes étapes :

Création de modèles, impliquant :
La construction d'un modèle avec des paramètres
Un ensemble de données pour entraîner le modèle (ou plusieurs ensembles)
Activation du modèle (utilisation du modèle) :
Nouvelles données sur lesquelles le modèle sera appliqué
KPI pour déterminer le comportement du modèle
Création des modèles
Un modèle est essentiellement une fonction avec des paramètres. Il sera alimenté par des données et donnera un résultat.

Les paramètres qui seront déterminés lors de la création du modèle sont fortement liés aux données utilisées pour entraîner l'algorithme.
Les inférences créées dans le modèle seront le reflet des informations contenues dans les données d'entraînement.
Les ensembles de données utilisés sont par définition une représentation partielle de la réalité. Ils sont susceptibles d'inclure des biais, tels que des biais cognitifs humains, ou des biais de collecte (par exemple: des données provenant d'un seul pays pour un produit qui sera utilisé dans le monde entier).
Un ensemble de données peut être biaisé de nombreuses façons, et les modèles construits à partir d'ensembles de données biaisées sont fortement susceptibles de créer des discriminations entre différentes populations (comme un data product accordant moins de prêts aux femmes qu'aux hommes parce qu'il est basé sur des données de travail historiques).
Activation des modèles
Une fois le modèle en production et utilisé dans une application réelle, il prévoira des résultats basés sur des données qui n'avaient jamais été vues auparavant.
Le seul moyen pour un data scientist de comprendre si le modèle formé comportera un biais pour certaines populations, est de construire des mesures autour du modèle. Plusieurs recherches ont commencé à identifier et à classer ces paramètres. Pour les comprendre, examinons les différentes définitions de l'équité.
Biais
Comme évoqué précédemment, Deux principaux types de biais peuvent être considérés :
Biais cognitif
Biais (statistique) lié au machine LEarning
Biais cognitif
La principale origine des préjugés, c'est nous, les êtres humains. Nous sommes remplis de préjugés. Des préjugés qui proviennent de notre histoire, de notre culture, de nos opinions, de notre moralité, de la méconnaissance d'un domaine spécifique...
Il existe une vaste littérature sur les préjugés cognitifs. Les principaux biais cognitifs peuvent être : les stéréotypes, les biais de perception sélective et de confirmation, et bien d'autres encore. L'article suivant donne une visualisation très agréable et approfondie des biais cognitifs :
https://www.sog.unc.edu/sites/www.sog.unc.edu/files/course_materials/Cognitive%20Biases%20Codex.pdf
Biais du Machine Learning
Les biais du machine learning proviennent généralement de problèmes introduits par la personne qui conçoit et/ou forme un modèle. Les développeurs peuvent soit créer des algorithmes qui reflètent des biais cognitifs involontaires, soit des préjugés de la vie réelle. Ils peuvent également introduire des biais car ils utilisent des ensembles de données incomplets, erronés ou préjudiciables pour former et/ou valider leurs modèles.
Nous sommes l'une des principales raisons pour lesquelles des biais apparaissent dans la création d'un algorithme. Pourquoi choisissons-nous un certain ensemble de données pour entraîner un algorithme ? Avons-nous fait une analyse approfondie d'un ensemble de données d'entraînement pour nous assurer que nous limitons les biais qu'il apportera à l'algorithme ?
https://lionbridge.ai/articles/7-types-of-data-bias-in-machine-learning/
Bien que ces biais soient souvent involontaires, les conséquences de leur présence dans les systèmes d'apprentissage automatique peuvent être importantes. Selon la manière dont les systèmes de machine learning sont utilisés, ces biais peuvent entraîner une diminution de la qualité de service, des ventes et des revenus, des actions déloyales ou éventuellement illégales et des conditions potentiellement dangereuses.
Prenons un exemple pour comprendre rapidement le concept de partialité. Un Data Scientist forme un modèle sur l'échantillon de gauche dans l'image ci-dessous pour construire un data product qui sera applicable à la population de droite.

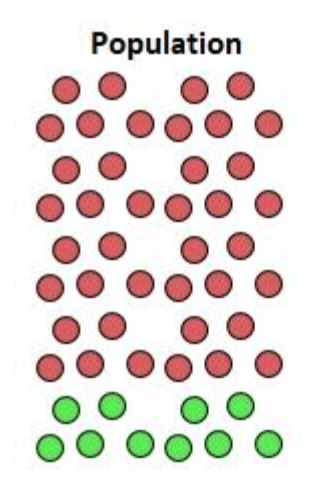
Nous avons ici un "biais d'échantillonnage", ou "biais de sélection", les résultats prédits par le modèle ne tenant pas compte de la bonne représentativité des caractéristiques au sein de la population.
Un autre exemple est celui de certains systèmes de reconnaissance faciale formés principalement sur des images d'hommes blancs. Ces modèles ont des niveaux de précision considérablement plus faibles avec les femmes et les personnes d'ethnies différentes.

Je vous invite à lire l'article suivant sur Joy Buolamwini, qui est à l'origine de l'étude ci-dessus : https://www.fastcompany.com/90525023/most-creative-people-2020-joy-buolamwini
Ses recherches ont contribué à persuader Amazon, IBM et Microsoft de mettre en sommeil la technologie de reconnaissance faciale.
Il y a beaucoup plus de préjugés que ce simple et unique préjugé. Un biais peut par exemple être classé en plusieurs catégories, et se rapporter à différentes parties du cycle de vie des data products, comme vous pouvez le voir dans l'image suivante.

Source : https://arxiv.org/pdf/1908.09635.pdf
Définitions de l'équité
L'équité algorithmique a commencé à attirer l'attention des chercheurs des communautés de l'IA, du génie logiciel et du droit, avec plus de vingt notions différentes d'équité proposées ces dernières années. Pourtant, il n'y a pas d'accord clair sur la définition à appliquer dans chaque situation. Les différences détaillées entre les multiples définitions sont également difficiles à saisir et les définitions peuvent être exclusives.
Plusieurs recherches ont été menées sur le sujet et ont tenté de définir l'équité d'un point de vue mathématique. Dans le document de recherche suivant https://fairware.cs.umass.edu/papers/Verma.pdf et dans plusieurs autres documents et articles, nous pouvons voir que la définition de l'équité n'est pas unique. Dans ce document, le chercheur conclut :
" ... Le classificateur est-il équitable ? Il est clair que la réponse à cette question dépend de la notion d'équité que l'on veut adopter. Nous pensons que des travaux supplémentaires sont nécessaires pour clarifier quelles définitions sont appropriées à chaque situation particulière. Nous avons l'intention de faire un pas dans cette direction en analysant systématiquement les rapports existants sur la discrimination des logiciels, en identifiant la notion d'équité utilisée dans chaque cas et en classant les résultats".
Vous pouvez également trouver dans les documents suivants des descriptions détaillées des définitions des préjugés et de l'équité qui sont assez communément acceptées :
Le tableau ci-dessous liste les définitions l'équité les plus utilisées. Elles sont applicables à un groupe ou à un individu :

Toutes les définitions ne sont pas compatibles les unes avec les autres. Certaines sont exclusives des autres (comme les Equalized Odds et la parité démographique, voir l'explication ci-dessous des 3 principales définitions). Une entreprise, ou une organisation, devra décider quelle définition s'applique à son (ses) produit(s).
Aequitas (une initiative du DSSG) a publié un excellent document sur les définitions de l'équité :

Concentrons-nous sur l'équité d'utilisation la plus courante :
La parité démographique,
Égalité des chances
“Equalized Odds”
Prenons un paramètre binaire (0/1), G (ex : sexe), que nous voulons protéger de la discrimination algorithmique. Pour simplifier, considérons seulement G comme paramètre. Nous avons affaire à deux groupes :
l'un est considéré comme protégé (ex : groupe masculin)
l'autre non protégée (groupe féminin)
Ensuite, nous considérons le résultat d'un classificateur binaire. Une des classes de sortie est considérée comme un résultat positif (ex : se faire embaucher) et l'autre comme un résultat négatif (ex : ne pas se faire embaucher).

Dans les data products complexes, nous n'avons généralement pas affaire à un seul algorithme, il peut y en avoir plusieurs utilisés en cascade ou en parallèle. La complexité pour atténuer les biais peut être énorme.
Outils et bibliothèques de machine learning pour la réduction des préjugés et l'équité
Si nous trouvons beaucoup de documents de recherche sur l'équité, les solutions et les outils directs pour les développeurs sont assez rares pour le moment.
Les grandes bibliothèques, telles que Scikit-learn, n'intègrent pas de mesures d'équité. Mais certains grands acteurs comme Google ou IBM, ou des initiatives isolées ont commencé à proposer des approches intéressantes.
La plupart d'entre elles se répartissent en trois catégories :
Prétraitement
Optimisation au moment de la formation
Post-traitement
Dans le tableau suivant, vous trouverez quelques indications sur la catégorie qui s'appliquerait à un algorithme ou à un processus d'apprentissage automatique. Pour plus de détails, je vous invite à parcourir le document suivant :
https://arxiv.org/pdf/1908.09635.pdf.

Comment prévenir les préjugés ?
La sensibilisation et la bonne gouvernance peuvent aider à prévenir les biais d'apprentissage de la machine.
Une organisation qui tient compte de la potentialité des biais dans ses data products dès la phase initiale de la conception de ses produits sera mieux équipée pour lutter contre tout biais qui pourrait être mis en œuvre.
La mise en place de meilleures pratiques serait nécessaire :
Définir une politique d'équité au sein de l'entreprise pour évaluer et définir la ou les mesures d'équité qui devraient être applicables à l'entreprise et à ses produits. Cela permettrait de donner les principales orientations et de définir les attentes.
Inclure des mesures d'équité dans la phase initiale de la conception de tout produit de données afin de s'assurer que l'entreprise est en mesure d'atténuer tout risque en matière d'équité
Pendant la phase de développement, sélectionnez des données d’entrainement représentatives et suffisamment importantes pour limiter l'apparition des biais habituels d'apprentissage machine (comme les biais d'échantillonnage ou les préjugés).
Effectuez des tests approfondis pour vous assurer que les résultats du produit ne reflètent pas les biais dus aux ensembles de données ou à l’entraintement du modèle
Surveillez les produits de données tels qu'ils sont utilisés dans la production pour vous assurer que les biais n'apparaissent pas avec le temps, car l'algorithme sera utilisé sur de nouvelles données jamais vues pendant la phase de formation. Pendant cette phase, il est important d'identifier tout modèle qui pourrait suggérer un biais possible.
Utilisez les ressources supplémentaires que nous décrirons dans la partie suivante de cet article pour examiner et inspecter les modèles.
Outils pour approcher l’équité en Machine Learning
La littérature sur l'équité a beaucoup augmenté depuis 1 ou 2 ans. Mais les bibliothèques ou les outils que les développeurs et les spécialistes des données peuvent utiliser sont encore rares.
Vous trouverez dans la partie suivante un aperçu et une comparaison de ces ressources.
https://www.linkedin.com/pulse/overview-some-available-fairness-frameworks-packages-murat-durmus/
https://analyticsindiamag.com/top-tools-for-machine-learning-algorithm-fairness/
Les différents outils offrent des mesures spécifiques, des possibilités de visualisation et de comparaison. Ils offrent soit une mise en œuvre efficace et évolutive de SHAP, soit sont joliment associés à SHAP.
(SHAP est basé sur le concept de la valeur de Shapley du domaine de la théorie des jeux coopératifs qui attribue à chaque caractéristique une valeur d'importance pour une prédiction particulière).

Outil Google What If
Google a mis en place des ressources très intéressantes pour mieux comprendre l'optimisation de l'équité, et visualiser les mesures de l'équité.
Comme première approche intéressante, je vous invite à jouer avec la page suivante, où vous verrez que l'optimisation pour l'équité est susceptible de réduire les performances globales du modèle. Il s'agira alors d'un choix de conception. https://research.google.com/bigpicture/attacking-discrimination-in-ml/
What If Tool est un outil de visualisation qui peut être utilisé dans un notebook Python pour analyser un modèle de machine learning.
Le site web suivant donne un aperçu rapide avec des démos sur les capacités de l'outil :
https://pair-code.github.io/what-if-tool/index.html#demos
https://pair-code.github.io/what-if-tool/ai-fairness.html
Vous y trouverez également une très bonne introduction à l'utilisation de WIT et SHAP pour l'optimisation de l'équité :
https://pair-code.github.io/what-if-tool/learn/tutorials/features-overview-bias/
IBM AI Fairness 360
https://arxiv.org/abs/1810.01943
https://github.com/Trusted-AI/AIF360
Le package AI Fairness 360 Python comprend un ensemble complet de mesures pour les ensembles de données et les modèles afin de tester les biais, des explications pour ces mesures et des algorithmes pour atténuer les biais dans les ensembles de données et les modèles.

FAIRLEARN
Fairlearn propose quelques outils qui peuvent aider à détecter et à atténuer les injustices dans les modèles. L'offre Fairlearn comprend deux éléments principaux :
L'évaluation de l'équité : Fairlearn propose un tableau de bord et un ensemble de mesures pour aider à évaluer l'équité d'un modèle.
L’atténuation de l'iniquité : Outre le tableau de bord et les mesures, Fairless propose plusieurs algorithmes qui peuvent être utilisés pour atténuer la discrimination des modèles (entrainement ou ou post-traitement)
Avec Fairlearn, vous pourrez :
mesurer l'équité en utilisant le widget du tableau de bord de fairlearn.
Améliorer l'équité pour les modèles formés en utilisant TresholdOptimizer
Former des modèles plus équitables grâce à GridSearch
L'article suivant donne un aperçu détaillé de Fairlearn :
Toutes les ressources sont disponibles à l'adresse suivante :
https://github.com/wmeints/fairlearn-demo
https://fairlearn.github.io/master/index.html
Sagemaker Clarifier
AWS a annoncé début décembre 2020 son nouveau module dans Sagemaker : Sagemaker Clarifier.
https://aws.amazon.com/blogs/aws/new-amazon-sagemaker-clarify-detects-bias-and-increases-the-transparency-of-machine-learning-models/
C'est très utile pour tous les data scientist travaillant déjà dans Sagemaker, car vous pourrezt :
Mesurer et évaluer plusieurs métriques liées à l’équité
Suivre régulièrement les prévisions de dérive des biais des modèles
Surveiller régulièrement les prédictions de dérive de l'attribution des caractéristiques.
Vous y trouverez le module complet : https://aws.amazon.com/sagemaker/clarify/
Vous trouverez à la page suivante une approche détaillée, étape par étape, pour appliquer certains des outils ci-dessus aux données du Compass :
https://medium.com/sfu-cspmp/model-transparency-fairness-552a747b444
Bibliography
La littérature sur l'équité du machine learning commence à être assez importante.
Si vous voulez en savoir plus, vous pouvez vous référer aux articles et documents suivants :
https://towardsdatascience.com/a-tutorial-on-fairness-in-machine-learning-3ff8ba1040cb
https://towardsdatascience.com/programming-fairness-in-algorithms-4943a13dd9f8
https://towardsdatascience.com/machine-learning-and-discrimination-2ed1a8b01038
Influence de la race sur la perception automatisée des émotions: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3281765
Document très détaillé : Social Data : Biais, pièges méthodologiques et limites éthiques
https://towardsdatascience.com/machine-learning-and-discrimination-2ed1a8b01038
Resources en Français :
Si vous souhaitez aller plus loin, vous pouvez vous référer aux supports de formation suivants :
Tutoriels vidéo
Supports de cours