Distillation de modèle et confidentialité
Cet article de blog est une introduction à la notion de distillation de modèle et son lien avec la privacy. Il a été écrit par Gijs Barmentlo dans le cadre de la saison 8 de Data For Good.
Cet article de blog a été traduit depuis sa version anglaise à l’aide d’outil automatique : un certain nombre de termes techniques anglais ont pu être traduits littéralement.

Introduction
Ces dernières années, l'apprentissage profond (deep learning) a obtenu des résultats impressionnants dans un large éventail de tâches, notamment la vision par ordinateur, le traitement du langage naturel et la reconnaissance vocale. Cependant, ces performances sont obtenues avec des modèles de grande taille qui sont coûteux en calcul, ce qui limite leur utilisation sur les appareils mobiles.
Pour réduire la taille des modèles, nous pouvons utiliser la distillation de modèles, qui est le processus de transfert de connaissances d'un grand modèle, le “teacher”, à un plus petit, le “student”. Il est possible de le faire sans diminuer sensiblement les performances, car les grands modèles n'utilisent souvent pas pleinement leur capacité de connaissance.
Distillation de modèles - Comment cela fonctionne-t-il ?
a. Approche de base - Apprendre des sorties du ”teacher”
Tout d'abord, le modèle “lourd” est entraîné sur les données. Une fois entraîné, il sera utilisé comme professeur pour un modèle plus petit.
Pour former le modèle “student”, nous propageons les données à travers les deux modèles et utilisons les sorties du teachers et les vérités de base pour calculer la perte et la rétropropagation dans le réseau du “student”.
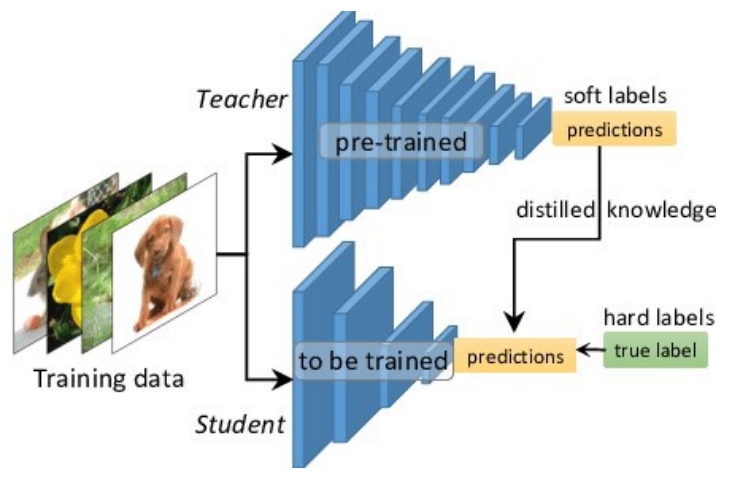
La fonction de perte globale est composée de la perte du student, basée sur la différence entre la prédiction du student et les vérités de base, et de la perte de distillation basée sur la différence entre les sorties du students et du teacher.
LKD=α*H(y,σ(zs)) +β*H(σ(zt;ρ),σ(zs;ρ))
Où H est la fonction de perte, y est l'étiquette de vérité terrain, σ est la fonction softmax paramétrée par la température ρ, α et β sont des coefficients, zs et zt sont les logits du student et du teacher respectivement.
Cette méthode montre l'intuition de base derrière la distillation du modèle student-teacher. Cependant, comme elle est uniquement basée sur la sortie finale du teacher, elle présente des problèmes de convergence lorsqu'elle est appliquée à des modèles profonds.
b. Apprentissage par indices - Établir la correspondance entre les couches
L'apprentissage par indices a été proposé pour compenser cette limitation et pour ajouter de la flexibilité. Il est également connu sous le nom de distillation basée sur les caractéristiques car le student apprend également la représentation des caractéristiques du teacher.

L'idée est d'ajouter une perte d'apprentissage des indices, basée sur la différence entre les couches d'indices et les couches guidées.
L(FT,FS) =D(TFt(FT),TFs(FS)
Où FT et FS sont les couches hint (teachers) et guidée (students). TFt et TFS sont des fonctions de transformation et de régression qui sont nécessaires car FS et FT n'ont pas la même forme. D est une fonction de distance (par exemple, L2).
Cela signifie que de nombreux éléments doivent être choisis afin de mettre en œuvre l'apprentissage par allusion : le transformateur, le régresseur, la couche guidée et la couche d'allusion. Diverses méthodes ont été proposées pour cela, mais le manque de théorie sur la façon dont les connaissances sont transférées rend difficile l'évaluation de ces différentes méthodes.
Exemples et performances
BERT, un modèle NLP de pointe, a été compressé avec succès grâce à la distillation de modèles. L'architecture générale de DistilBERT est similaire à celle de BERT avec l'incorporation de type token et le pooler supprimés et avec deux fois moins de couches.
Empiriquement, ils ont constaté que la réduction du nombre de couches avait plus d'impact sur l'efficacité du calcul que la réduction des dimensions des couches, pour un budget de paramètres fixe.
Ils ont utilisé le fait que la dimensionnalité était la même pour initialiser DistilBERT avec les poids des couches impaires de BERT.
En termes de performances, DistilBERT conserve 97 % des performances de BERT sur le benchmark GLUE tout en ayant 40 % de paramètres en moins et un temps d'inférence 39 % plus court.
Déploiement mobile et problèmes de confidentialité
a. Problèmes de confidentialité et de propriété intellectuelle
En pratique, les développeurs d'applications collectent souvent des données auprès de leurs utilisateurs pour entraîner leur DNN, dont certaines peuvent être des données sensibles. La publication d'un modèle entraîné sur ces données peut poser des problèmes de confidentialité car un adversaire pourrait récupérer les données encodées dans le modèle (Abadi et al. 2016).
En outre, la publication des modèles DNN ouvre la possibilité de piratage et constitue une menace pour la propriété intellectuelle du développeur.
b. Une solution proposée - le cadre RONA
Le framework RONA, pour pRivate mOdelcompressioN frAmework, combine l'apprentissage student-teacher et la confidentialité différentielle pour entraîner des modèles à la fois légers et sécurisés.
RONA utilise 3 modules principaux : la compression de modèles basée sur la distillation de connaissances, la perturbation de connaissances à confidentialité différentielle et la sélection d'échantillons de requêtes.
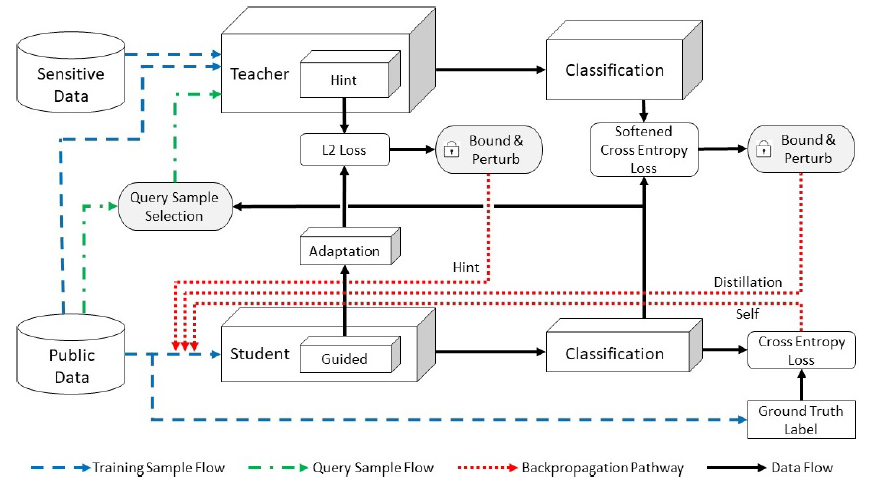
Ce cadre présente quelques particularités qui permettent de garantir la confidentialité :
Le teacher est formé en utilisant les données publiques et sensibles, mais les données sensibles ne seront jamais vues directement par le réseau students.
Lorsque le teacher a appris à partir des données sensibles, un bruit gaussien est injecté dans l'indice et les pertes de distillation avant d'être rétro-propagé pour mettre à jour le student.
Conclusion
La distillation de modèle est susceptible de devenir une méthode utile pour la compression de modèle, elle diffère des autres méthodes telles que l'élagage et la quantification car elle modifie l'architecture du modèle.
Il n'existe pas encore de norme établie pour la distillation de modèles, il s'agit actuellement d'un domaine davantage axé sur la recherche. Cependant, la technique est susceptible de mûrir à mesure que le déploiement de modèles sur des appareils mobiles devient plus courant.
Compte tenu des problèmes de confidentialité et de propriété intellectuelle que pose la diffusion directe des modèles, les cadres tels que RONA, qui offrent des garanties de confidentialité, deviendront un outil essentiel.