Consortiums entre concurrents
Les algorithmes de machine learning, pour accroître leurs performances, nécessitent une grande quantité de données. Mais, au sein d’une industrie ces données sont souvent éparpillées entre différents acteurs qui ne peuvent se permettre de partager ce qui est le cœur de leur business.
Comment accroître les performances de toute une industrie grâce au machine learning, sans mettre en danger la sécurité des données de chaque industriel ?

Un nouveau modèle de collaboration
Elaborer des modèles de machine learning performants à partir de données de plusieurs entreprises et organismes partenaires, sans exposer les jeux de données concernés, et permettre ainsi aux participants de préserver leurs secrets industriels.
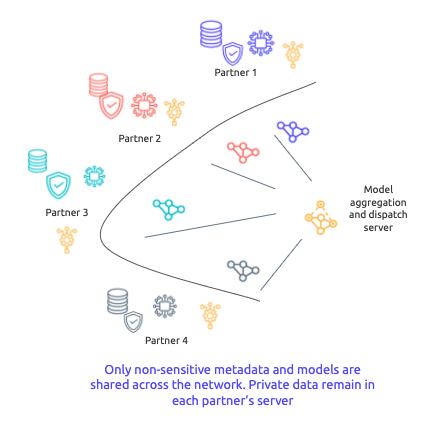
Protéger les données
Les données sensibles restent sur les infrastructures propres à chaque partenaire membre du consortium. Seules les méta-données et les modèles sont partagés entre les différents partenaires.
Chaque partenaire préserve la valeur de ses données.

Garantir la traçabilité
Basée sur Hyperledger Fabric, le registre distribué au sein de Substra permet de gérer les droits et autorisations de chaque partenaire et de tracer toutes les actions réalisées au sein du consortium.
Aucune action ne peut être réalisée sans l’accord des participants du consortium.

Co-construire des modèles
Grâce au transfer learning, les partenaires peuvent décider de ne partager qu’une partie du modèle, les couches basses constituant un tronc commun, les couches hautes restant privées.
Seul un tronc commun est partagé pour renforcer la confidentialité des données.

Réinventer votre
écosystème
Le framework Substra permet de créer de nouveaux partenariats autour du machine learning tout en garantissant la sécurité des données, bénéficiant à l’ensemble des participants.
Vous voulez en savoir plus ? Découvrez comment le projet MELLODDY rassemble un consortium de 17 partenaires dans l’industrie de la santé en Europe pour accélérer la découverte de nouvelles molécules.