Collaborations entre producteurs de données et data scientists
Pour développer de nouveaux algorithmes ou améliorer leurs modèles existants, les data scientists ont besoin d’une quantité importante de données. Mais celles-ci ne leurs sont parfois pas accessibles car trop confidentielles pour êtres partagées par l’organisme qui les a collectées. Elles peuvent être de plus disséminées au sein d’un nombre important de fournisseurs différents.
Comment donner accès aux startups, entreprises, chercheurs, à de nouvelles données sans compromettre la confidentialité de celles-ci ?

Une nouvelle définition de l’accès à la donnée
Avec Substra, les fournisseurs de données peuvent mettre à disposition des data scientists leurs données pour créer de nouveaux modèles sans jamais que ceux-ci puissent les lire, et sans jamais déplacer la moindre donnée.
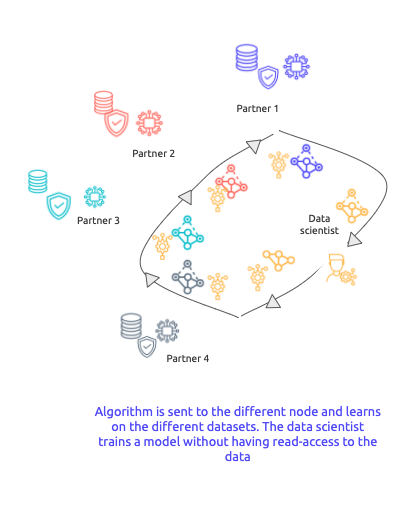
Déplacer les algos et les modèles, pas les données
Grace au distributed learning, il n’est pas nécessaire de transférer les données vers un serveur centralisé. Les données restent sur les infrastructures propres des gestionnaires de données. Ce sont les algorithmes qui se déplacent.
Les données restent immobiles. Seuls les modèles et algorithmes se déplacent.

Collaborer avec des producteurs de données parfois concurrents
Pour vos besoins de ML, vous nouez des collaborations avec des gestionnaires de données, parfois concurrents. Avec un modèle où les données sont distribuées, chaque fournisseur préserve ses données.
L’absence de nécessité de centraliser des données de concurrents permet de nouvelles collaborations.

Valoriser vos données à leur juste valeur
Chaque producteur de données peut être rémunéré selon sa contribution à la performance du modèle. Nous travaillons sur différentes mesures de la contributivité des jeux de données (voir sur Github).
Les producteurs de données peuvent valoriser à hauteur de leur contribution leurs données.

Explorez de nouveaux horizons
Données trop confidentielles, données trop dispersées entre divers organismes…
Avec le framework Substra, ces obstacles ne seront plus un frein à vos collaborations de data science.
En tant qu’organisme gestionnaire de données, valoriser enfin vos données en toute sécurité, et à leur juste valeur.
Vous voulez en savoir plus ? Découvrez comment le consortium HealthChain rassemble des hôpitaux, des laboratoires de recherche, de jeunes entreprises innovantes et Substra Foundation dans l’objectif d’élaborer des modèles d’IA sur des données cliniques.